
Note: Since the code in this post is outdated, as of 3/4/2019 a new post on Scraping Amazon and Sentiment Analysis (along with other NLP topics such as Word Embedding and Topic Modeling) are available through the links!
How to Scrape the Web in R
Most things on the web are actually scrapable. By selecting certain elements or paths of any given webpage and extracting parts of interest (also known as parsing), we are able to obtain data. A simple example of webscraping in R can be found in this awesome blog post on R-bloggers.
We will use Amazon for an example in this post. Let’s say we have the ASIN code of a product B0043WCH66. Let’s scrape the product name of this on Amazon. The URL of Amazon’s product pages are easy to build; simply concatenate the ASIN code to the “base” URL as such: https://www.amazon.com/dp/B0043WCH66.
We build the URL, and point to a specific node #productTitle of the HTML web page using the CSS selector (read about CSS Selector and how to obtain it using the SelectorGadget here). Finally, we clean and parse the text to obtain just the product name:
pacman::p_load(XML, dplyr, stringr, rvest, audio)
#Remove all white space
trim <- function (x) gsub("^\\s+|\\s+$", "", x)
prod_code = "B0043WCH66"
url <- paste0("https://www.amazon.com/dp/", prod_code)
doc <- read_html(url)
#obtain the text in the node, remove "\n" from the text, and remove white space
prod <- html_nodes(doc, "#productTitle") %>% html_text() %>% gsub("\n", "", .) %>% trim()
prod
## [1] "Bose® MIE2i Mobile Headset"
With this simple code, we were able to obtain the product name of this ASIN code.
Now say we want to scrape more data of the product Bose® MIE2i Mobile Headset. We will use a function amazonscraper (available on my github). We will pull the first 10 pages of reviews:
#Source funtion to Parse Amazon html pages for data
source("https://raw.githubusercontent.com/rjsaito/Just-R-Things/master/Text%20Mining/amazonscraper.R")
pages <- 10
reviews_all <- NULL
for(page_num in 1:pages){
url <- paste0("http://www.amazon.com/product-reviews/",prod_code,"/?pageNumber=", page_num)
doc <- read_html(url)
reviews <- amazon_scraper(doc, reviewer = F, delay = 2)
reviews_all <- rbind(reviews_all, cbind(prod, reviews))
}
## 'data.frame': 100 obs. of 9 variables: ## $ prod : chr "Bose® MIE2i Mobile Headset" "Bose® MIE2i Mobile Headset" "Bose® MIE2i Mobile Headset" "Bose® MIE2i Mobile Headset" ... ## $ title : chr "Clarity, Comfort, Construction" "Awesome!" "Bose's signature sound works in its advantage" "Very disappointed as the wires are not lasting." ... ## $ author : chr "Richard Blumberg" "James R. Spitznas" "John Barta" "Rick Gillis" ... ## $ date : chr "November 20, 2010" "December 28, 2010" "June 29, 2011" "September 6, 2012" ... ## $ ver.purchase: int 1 0 0 1 1 0 1 0 1 0 ... ## $ format : chr "Package Type: Standard Packaging" "Package Type: Standard Packaging" "Package Type: Standard Packaging" "Package Type: Standard Packaging" ... ## $ stars : int 5 4 4 2 1 1 1 1 5 1 ... ## $ comments : chr "These are the sixth or seventh set of earbuds I've had for a succession of iPods and iPhones. I'm slightly hard of hearing, and"| __truncated__ "I purchased these to replace the Sennheiser's that I had been using at the gym, cycling and skiing. BTW I will never buy anoth"| __truncated__ "When you take 100 dollar earbuds the biggest hurdle is the technology. No matter how accurate the earbud WANTS to be, its going"| __truncated__ "While I would normally boast of the Bose name, this time I am let down. I have had these earphones for just over a year, and I "| __truncated__ ... ## $ helpful : int 577 63 166 18 59 14 11 177 93 23 ...
With amazonscraper, we obtained several values for each of the first 100 reviews of the product.
Sentiment Analysis in R
Now that we were able to obtain all this data, what can we do with this? Sure, we can read through all these reviews to see what people are saying about this product or how they feel about it, but that doesn’t seem like a good use of time. That’s where Sentiment Analysis comes in handy.
Sentiment Analysis is a Natural Langauge Processing method that allows us to obtain the general sentiment or “feeling” on some text. Sure we can just look at the star ratings themselves, but actually star ratings are not always consistent with the sentiment of the reviews. Sentiment is measured on a polar scale, with a negative value representing a negative sentiment, and positive value representing a positive sentiment.
Package ‘sentimentr’ allows for quick and simple yet elegant sentiment analysis, where sentiment is obtained on each sentences within reviews and aggregated over the whole review. In this method of sentiment analysis, sentiment is obtained by identifying tokens (any element that may represent a sentiment, i.e. words, punctiation, symbols) within the text that represent a postive or negative sentiment, and scores the text based on number of positive tokens, negative tokens, length of text, etc:
pacman::p_load_gh("trinker/sentimentr")
sent_agg <- with(reviews_all, sentiment_by(comments))
head(sent_agg)
## element_id word_count sd ave_sentiment ## 1: 1 670 0.4730184 0.16014619 ## 2: 2 373 0.2602493 0.06357467 ## 3: 3 724 0.3943997 0.26884453 ## 4: 4 164 0.1905274 -0.01444510 ## 5: 5 406 0.4812642 0.03993990 ## 6: 6 112 0.3986540 0.03549016
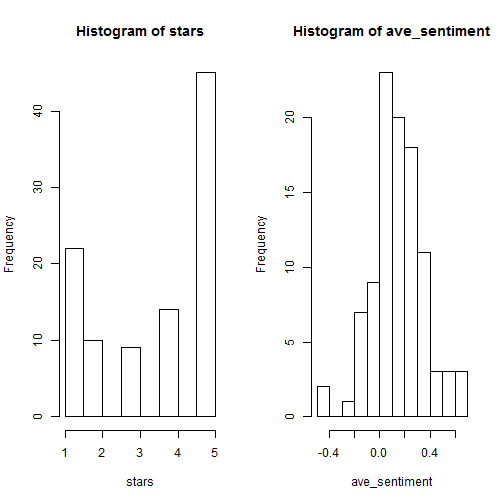
par(mfrow=c(1,2))
with(reviews_all, hist(stars))
with(sent_agg, hist(ave_sentiment))
mean(reviews_all$stars)
## [1] 3.5
mean(sent_agg$ave_sentiment)
## [1] 0.1512848
You can see here there is a major inconsistency between stars and sentiment, even just by comparing the distrubution of both. In addition, while the average star rating is 3.5, the average sentiment is actually distrubuted around near 0 (neutral sentiment).
Now let’s see how these sentiments are actually being determined at the sentence level. Let’s obtain the reviews with highest sentiment and lowest sentiment, and take a look. The function highlight in sentimentr allows us to do this easisly.
best_reviews <- slice(reviews_all, top_n(sent_agg, 3, ave_sentiment)$element_id) with(best_reviews, sentiment_by(comments)) %>% highlight()

worst_reviews <- slice(reviews_all, top_n(sent_agg, 3, -ave_sentiment)$element_id) with(worst_reviews, sentiment_by(comments)) %>% highlight()

While the positive reviews have all positive sentiments, the negative reviews are actually a mix of positive and negative, where the negative significantly outweights the positive.
While these sentiments do not perfectly capture the true sentiments in these reviews, it is a quick and decently accurate method to quickly obtain the sentiments of these reviewers.
This method of sentiment analysis is a simple approach, and there are a number of widely known methods of sentiment anaylsis (one of which I am interested is in a machine learning approach to sentiment analysis) that involve analysing text by considering sequence of words and relationships between these sequence of words (here is a basic explanation in this youtube video).

Hey Riki, cool stuff! I have one question, as I am not as familiar with R as you: Is it possible to save the data for each ASIN/Review Dataset as a csv for latter transportation to other statistics programs? Thanks for your help! Best, Alex
LikeLike
This is really late but yes, you can!
use this code
write.csv(reviews_all,’reviews.csv’)
It will save in your computer’s R working directory
LikeLiked by 1 person
I have a problem when I run this: “Error in data.frame(title, author, date, ver.purchase, format, stars, :
arguments imply differing number of rows: 10, 9”
What this means? Thank you very much!
LikeLike
This occurs most likely because one (or more) of the variables you are scraping had a missing value from the original page on Amazon, thus skipped over a value and only pulled 9 values instead of 10 – you might want to look into each variable and see which one is missing a a value.
LikeLike
Another trick I like to use is:
write.csv(reviews_all, file.choose(new = T))
This will open an interactive window and will prompt you to select the folder you want to save the file in and create a file name.
LikeLike
Not sure why, but this code works inconsistently. Curious if maybe it’s a server issue.
LikeLiked by 2 people
If you are referring to the the web scraping – there is a caveat on pulling large amounts of data as websites typically don’t want people rendering new pages so much and so frequently, – you’ll want to consider throttling your calls (i.e. add a sleep time of a couple seconds in between each page call).
LikeLike
This isn’t working for me either on any product I’ve tried.
Error in data.frame(title, author, date, ver.purchase, format, stars, :
arguments imply differing number of rows: 10, 0
LikeLike
This is really cool. Works fine for me. I was searching for this from a long time.
LikeLiked by 1 person
Hello Riki, thanks for the article. I have a question, I’ve seen this website which says that anonymizes your data https://proxycrawl.com how would you use it for amazon following your tutorial? Thanks
LikeLike
This code is not working with the error
Error in data.frame(stars, comments, helpful, stringsAsFactors = F) :
arguments imply differing number of rows: 10, 0
LikeLike
Did you find a solution?
LikeLike
me too i have the same error , did u find solution????
LikeLike
I am getting the same error as many commenters – I have included it below with traceback:
Error in data.frame(title, author, date, ver.purchase, format, stars, :
arguments imply differing number of rows: 8, 0
3. stop(gettextf(“arguments imply differing number of rows: %s”,
paste(unique(nrows), collapse = “, “)), domain = NA)
2. data.frame(title, author, date, ver.purchase, format, stars,
comments, helpful, stringsAsFactors = F) at amazonscraper.R#57
1. amazon_scraper(doc, reviewer = F, delay = 2)
Any suggestions on how to debug this would be appreciated. Does the function itself have to be modified? Is there a problem with how the data is being appended? I have tried this with multiple different products.
LikeLike
To follow up on the above – I looked further and found that when the code ran, for “author” and “helpful” the values were not being registered correctly.
author the output resulted in:
character(0)
helpful the output resulted in:
numeric(0)
When i commented out the lines of code pulling this data, the code ran fine. However I would like to pull data from the “helpful” field. I am not familiar with CSS selector but I think the code for these two fields has to be modified to pull this data correctly. Can anyone advise me as to how to do that?
LikeLike
Hi everyone,
I’m happy to announce that I’ve updated the Amazon web scraping R function in my re-release version of this post. Please visit the link below to find the update:
https://justrthings.com/2019/03/03/web-scraping-amazon-reviews-march-2019/
LikeLike
Amazing article, worth reading.I was searching for info like this for a long time! Keep those posts coming! Retailgators helps you scrape data from all websites like Amazon. It’s specially designed to make data scraping a totally painless exercise.
Know more here: Amazon Product Data Scraper
LikeLike